An introduction to generalized hypergeometric ensembles (gHypEG) regressions.
Giona Casiraghi
Chair of Systems Design, ETH Zurich, Switzerlandgcasiraghi@ethz.ch
Laurence Brandenberger
Chair of Systems Design, ETH Zurich, Switzerlandlbrandenberger@ethz.ch
2026-02-05
Tutorial_NRM.RmdIntroduction
The Package is used to run inferential models on multi-edge networks. This vignette guides through the data preparation and model estimation and assessment steps needed to perform network regressions on multi-edge networks. This vignette is split into 3 distinct parts
- Part 1: Data preparation
- Part 2: Running gHypEG regressions
- Part 3: Model assessment, simulations and goodness-of-fit
The vignette builds on a multi-edge network of Swiss members of Parliament. The data set is contained in the package for easy loading. The data set records co-sponsorship activities of 163 members of the Swiss National Council (in German: Nationalrat). Whenever a member of parliament (MP) drafts a new legislation (or bill), poses a question to the Federal Council (in German: Bundesrat), issues a motion or petition, they are allowed to add co-signatories (or co-sponsors) to the proposal. These co-sponsorship signatures act as a measure of support and signals the relevance of the proposal. As MPs can submit multiple proposals during the course of their service in parliament, each MP can support another MP multiple times, resulting in a multi-edge network of support among MPs.
Part 1: Data preparation
Loading package and data
library(ghypernet)
library(texreg, quietly = TRUE) # for regression tables
#> Version: 1.39.5
#> Date: 2025-12-21
#> Author: Philip Leifeld (University of Manchester)
#>
#> Consider submitting praise using the praise or praise_interactive functions.
#> Please cite the JSS article in your publications -- see citation("texreg").
library(ggplot2) # for plotting
library(ggraph) #for network plots using ggplot2After loading the package, the included data set on Swiss MPs can be used (already lazy loaded).
The data set contains four objects:
- cospons_mat: contains the adjacency matrix of 163 x 163 MPs. It contains the number of times one MP (rows) supports the submitted proposals of another MP (columns).
- dt: contains different attributes of the 163 MPs, such as their names, their party affiliation (variable: party), their parliamentary group affiliation (variable: parlGroup), the Canton (or state) they represent (variable: canton), their gender (variable: gender) and date of birth (variable: birthdate).
- dtcommittee: a list of committees each MP was part of during their stay in parliament
- onlinesim_mat: a similarity matrix of how similar two MPs are in their online social media presence (shared supportees).
Network data manipulations
The above data is coded in an adjacency matrix. However, most often, network data is stored in the more efficient edge list format. Two functions help move from one format to another:
el <- adj2el(cospons_mat, directed = TRUE)The adj2el()-function transforms an adjacency matrix
into an edgelist. By specifying directed = FALSE, only the
top triangle of the adjacency matrix is stored in the edgelist (making
it more efficient to handle, especially for large networks).
Edgelists also allow you to check basic statics about your network, such as average degree or the degree distribution.
summary(el$edgecount)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1.000 1.000 2.000 3.854 4.000 75.000The function el2adj transforms an edgelist into an
adjacency matrix.
Since edgelists (often) do not store isolate nodes in the network,
the function takes a nodes-attribute. By specifying the
nodes attribute, all all nodes (including isolate nodes) are included in
the adjacency matrix.
identical(cospons_mat, adj_mat)
#> [1] TRUECompiling nodal attribute data
When preparing nodal attribute data, particular attention has to be
given to the ordering of the two data sets (the adjacency matrix and the
attribute data set). Testing whether the adjacency matrix and the
attribute data are ordered by the same identifiers (here by the ID codes
of the individual MPs, dt$idMP), attribute-based
independent and control variables will correspond with the dependent
variable.
In case, the above test-code yields FALSE, the attribute
data needs to be ordered.
Let’s assume, our attribute data set dt_unsorted is
sorted differently:
dt_unsorted <- dt[order(dt$firstName),]
identical(rownames(cospons_mat), dt_unsorted$idMP)
#> [1] FALSEThe simplest way is to proceed is to create a new data frame with the rownames (or colnames) of the adjacency matrix, then merging the attribute data in.
dtsorted <- data.frame(idMP = rownames(cospons_mat))
dtsorted <- dplyr::left_join(dtsorted, dt_unsorted, by = "idMP")
identical(dt$idMP, dtsorted$idMP)
#> [1] TRUELearn more about data joins here.
Independent and control variables
To estimate effects of endogenous and exogenous factors (i.e., independent and control variables) on the multi-edge network, covariates have to be fed into the gHypEG regression as matrices with the same dimensions as the multi-edge network (i.e., the dependent variable).
Additionally, it is prudent to make sure that all covariates have the same row- and column-names:
The role of zero-values in covariates
The gHypEG regression is zero-sensitive. Zero value entries in covariates signify structural zeros and are not considered in the estimation process. Therefore, all zero-values that do not signify structural zeros need to be recoded. The best solution is to the define a dummy variable that encodes zero and non-zero values to be used together with the covariate of interest. In this way, zero values are accounted separately in the regression process and do not enforce structural zeroes in the network.
Change statistics to calculate endogenous network statistics
Change statistics (or change scores) can be used to model endogenous network properties in inferential network models [@snijders2006new, @hunter2008goodness, @krivitsky2011adjusting]. For each dyad in the multi-edge network, the change statistic captures the (un-)weighted values of additional edges involved in the interested network pattern. See Brandenberger et al. [-@brandenberger2019quantifying] for additional information on change statistics for multi-edge networks.
Reciprocity
The reciprocity_stat()-function can be used to calculate
weighted reciprocity change statistic. Since it’s dyad-independent, it
can be used as a predictor in the gHypEG regression.
The function takes either a matrix or an edgelist. If an edgelist is
provided, the nodes-object can be specified again to ensure
that isolates are included as well.
recip_cospons <- reciprocity_stat(cospons_mat)
recip_cospons[1:5, 1:3]
#> Andreas Broennimann Ueli Maurer Markus Hutter
#> Andreas Broennimann 0 0 0
#> Ueli Maurer 0 0 0
#> Markus Hutter 2 1 0
#> Hansruedi Wandfluh 0 1 0
#> Thomas Matter 0 0 0The resultant matrix measures reciprocity by checking for each dyad , how many edges were drawn from . If reciprocity is a driving force in the network, taking the transpose of the matrix should correlate strongly with the co-sponsorship matrix.
The zero_values-argument allows for the specification of
minimum values. By default, 0 used.
Triadic closure
The sharedPartner_stat()-function provides change
statistics to check your multi-edge network for meaningful triadic
closure effects. Triadic closure refers to the important tendency
observed in social networks to form triangles, or triads, between three
nodes
,
and
.
If dyad
are connected, and dyad
are connected, there is a strong tendency in some social networks that
dyad
also shares an edge (see Figure 1a and 1b).
The sharedPartner_stat()-function uses the concept of
shared partner statistics to calculate the tendencies of nodes in
multi-edge networks to re-inforce triangular structures (see Figure
1c).
Figure 1: Triadic closure: (a) undirected triangle, (b) transitive triplet, (c) edge-wise shared partners. Source: Brandenberger et al. [-@brandenberger2019quantifying].
For undirected multi-edge networks, the statistic measures for each dyad —regardless of whether or not share edges or not—how many shared partners both nodes and have in common.
If the option weighted = FALSE is specified, the raw
number of shared partners
is reported in the shared partner matrix. For dense multi-edge networks,
this statistic is not meaningful enough (since all dyads share at least
one edge in a complete graph) to examine meaningful triadic closure. The
option weighted = TRUE therefore calculates a weighted
shared partner statistic, where edge counts are taken into consideration
as well (min(edgecount(i, k), edgecount(j, k))) [see @brandenberger2019quantifying].
shp_cospons_unweighted <- sharedPartner_stat(cospons_mat, directed = TRUE, weighted = FALSE)
#> | | | 0% | | | 1% | |= | 1% | |= | 2% | |== | 2% | |== | 3% | |=== | 4% | |=== | 5% | |==== | 6% | |===== | 7% | |====== | 8% | |====== | 9% | |======= | 9% | |======= | 10% | |======= | 11% | |======== | 11% | |======== | 12% | |========= | 12% | |========= | 13% | |========== | 14% | |========== | 15% | |=========== | 16% | |============ | 17% | |============= | 18% | |============= | 19% | |============== | 20% | |=============== | 21% | |=============== | 22% | |================ | 22% | |================ | 23% | |================= | 24% | |================= | 25% | |================== | 25% | |================== | 26% | |=================== | 27% | |==================== | 28% | |==================== | 29% | |===================== | 30% | |====================== | 31% | |====================== | 32% | |======================= | 32% | |======================= | 33% | |======================= | 34% | |======================== | 34% | |======================== | 35% | |========================= | 35% | |========================= | 36% | |========================== | 37% | |=========================== | 38% | |=========================== | 39% | |============================ | 40% | |============================= | 41% | |============================= | 42% | |============================== | 42% | |============================== | 43% | |=============================== | 44% | |=============================== | 45% | |================================ | 45% | |================================ | 46% | |================================= | 47% | |================================= | 48% | |================================== | 48% | |================================== | 49% | |=================================== | 50% | |==================================== | 51% | |==================================== | 52% | |===================================== | 52% | |===================================== | 53% | |====================================== | 54% | |====================================== | 55% | |======================================= | 55% | |======================================= | 56% | |======================================== | 57% | |======================================== | 58% | |========================================= | 58% | |========================================= | 59% | |========================================== | 60% | |=========================================== | 61% | |=========================================== | 62% | |============================================ | 63% | |============================================= | 64% | |============================================= | 65% | |============================================== | 65% | |============================================== | 66% | |=============================================== | 66% | |=============================================== | 67% | |=============================================== | 68% | |================================================ | 68% | |================================================ | 69% | |================================================= | 70% | |================================================== | 71% | |================================================== | 72% | |=================================================== | 73% | |==================================================== | 74% | |==================================================== | 75% | |===================================================== | 75% | |===================================================== | 76% | |====================================================== | 77% | |====================================================== | 78% | |======================================================= | 78% | |======================================================= | 79% | |======================================================== | 80% | |========================================================= | 81% | |========================================================= | 82% | |========================================================== | 83% | |=========================================================== | 84% | |============================================================ | 85% | |============================================================ | 86% | |============================================================= | 87% | |============================================================= | 88% | |============================================================== | 88% | |============================================================== | 89% | |=============================================================== | 89% | |=============================================================== | 90% | |=============================================================== | 91% | |================================================================ | 91% | |================================================================ | 92% | |================================================================= | 93% | |================================================================== | 94% | |=================================================================== | 95% | |=================================================================== | 96% | |==================================================================== | 97% | |==================================================================== | 98% | |===================================================================== | 98% | |===================================================================== | 99% | |======================================================================| 99% | |======================================================================| 100%
shp_cospons_unweighted[1:5, 1:3]
#> Andreas Broennimann Ueli Maurer Markus Hutter
#> Andreas Broennimann 0 13 23
#> Ueli Maurer 13 0 15
#> Markus Hutter 23 15 0
#> Hansruedi Wandfluh 24 15 45
#> Thomas Matter 0 0 1
shp_cospons_weighted <- sharedPartner_stat(cospons_mat, directed = TRUE)
#> | | | 0% | | | 1% | |= | 1% | |= | 2% | |== | 2% | |== | 3% | |=== | 4% | |=== | 5% | |==== | 6% | |===== | 7% | |====== | 8% | |====== | 9% | |======= | 9% | |======= | 10% | |======= | 11% | |======== | 11% | |======== | 12% | |========= | 12% | |========= | 13% | |========== | 14% | |========== | 15% | |=========== | 16% | |============ | 17% | |============= | 18% | |============= | 19% | |============== | 20% | |=============== | 21% | |=============== | 22% | |================ | 22% | |================ | 23% | |================= | 24% | |================= | 25% | |================== | 25% | |================== | 26% | |=================== | 27% | |==================== | 28% | |==================== | 29% | |===================== | 30% | |====================== | 31% | |====================== | 32% | |======================= | 32% | |======================= | 33% | |======================= | 34% | |======================== | 34% | |======================== | 35% | |========================= | 35% | |========================= | 36% | |========================== | 37% | |=========================== | 38% | |=========================== | 39% | |============================ | 40% | |============================= | 41% | |============================= | 42% | |============================== | 42% | |============================== | 43% | |=============================== | 44% | |=============================== | 45% | |================================ | 45% | |================================ | 46% | |================================= | 47% | |================================= | 48% | |================================== | 48% | |================================== | 49% | |=================================== | 50% | |==================================== | 51% | |==================================== | 52% | |===================================== | 52% | |===================================== | 53% | |====================================== | 54% | |====================================== | 55% | |======================================= | 55% | |======================================= | 56% | |======================================== | 57% | |======================================== | 58% | |========================================= | 58% | |========================================= | 59% | |========================================== | 60% | |=========================================== | 61% | |=========================================== | 62% | |============================================ | 63% | |============================================= | 64% | |============================================= | 65% | |============================================== | 65% | |============================================== | 66% | |=============================================== | 66% | |=============================================== | 67% | |=============================================== | 68% | |================================================ | 68% | |================================================ | 69% | |================================================= | 70% | |================================================== | 71% | |================================================== | 72% | |=================================================== | 73% | |==================================================== | 74% | |==================================================== | 75% | |===================================================== | 75% | |===================================================== | 76% | |====================================================== | 77% | |====================================================== | 78% | |======================================================= | 78% | |======================================================= | 79% | |======================================================== | 80% | |========================================================= | 81% | |========================================================= | 82% | |========================================================== | 83% | |=========================================================== | 84% | |============================================================ | 85% | |============================================================ | 86% | |============================================================= | 87% | |============================================================= | 88% | |============================================================== | 88% | |============================================================== | 89% | |=============================================================== | 89% | |=============================================================== | 90% | |=============================================================== | 91% | |================================================================ | 91% | |================================================================ | 92% | |================================================================= | 93% | |================================================================== | 94% | |=================================================================== | 95% | |=================================================================== | 96% | |==================================================================== | 97% | |==================================================================== | 98% | |===================================================================== | 98% | |===================================================================== | 99% | |======================================================================| 99% | |======================================================================| 100%
shp_cospons_weighted[1:5, 1:3]
#> Andreas Broennimann Ueli Maurer Markus Hutter
#> Andreas Broennimann 0 19 74
#> Ueli Maurer 19 0 19
#> Markus Hutter 74 19 0
#> Hansruedi Wandfluh 79 33 96
#> Thomas Matter 0 0 1For directed multi-edge networks, the option triad.type
allows for two more specialized shared partner statistics: incoming and
outgoing shared partners. Assume dyad
have shared partner
in common. For triad.type = "incoming", it is assumed that
ties to
and
(= edges
and
are present). In the co-sponsorship example, this measures whether nodes
and
are likely to support each other, if they both are supported by the same
other node/s
.
For triad.type = "outgoing", it is assumed that
and
both tie to
(regardless of whether
also ties to
or
).
In other words, for outgoing- shared partners, for dyad
,
we check whether edges
and
are present.
shp_cospons_incoming <- sharedPartner_stat(cospons_mat, directed = TRUE,
triad.type = 'directed.incoming')
#> | | | 0% | | | 1% | |= | 1% | |= | 2% | |== | 2% | |== | 3% | |=== | 4% | |=== | 5% | |==== | 6% | |===== | 7% | |====== | 8% | |====== | 9% | |======= | 9% | |======= | 10% | |======= | 11% | |======== | 11% | |======== | 12% | |========= | 12% | |========= | 13% | |========== | 14% | |========== | 15% | |=========== | 16% | |============ | 17% | |============= | 18% | |============= | 19% | |============== | 20% | |=============== | 21% | |=============== | 22% | |================ | 22% | |================ | 23% | |================= | 24% | |================= | 25% | |================== | 25% | |================== | 26% | |=================== | 27% | |==================== | 28% | |==================== | 29% | |===================== | 30% | |====================== | 31% | |====================== | 32% | |======================= | 32% | |======================= | 33% | |======================= | 34% | |======================== | 34% | |======================== | 35% | |========================= | 35% | |========================= | 36% | |========================== | 37% | |=========================== | 38% | |=========================== | 39% | |============================ | 40% | |============================= | 41% | |============================= | 42% | |============================== | 42% | |============================== | 43% | |=============================== | 44% | |=============================== | 45% | |================================ | 45% | |================================ | 46% | |================================= | 47% | |================================= | 48% | |================================== | 48% | |================================== | 49% | |=================================== | 50% | |==================================== | 51% | |==================================== | 52% | |===================================== | 52% | |===================================== | 53% | |====================================== | 54% | |====================================== | 55% | |======================================= | 55% | |======================================= | 56% | |======================================== | 57% | |======================================== | 58% | |========================================= | 58% | |========================================= | 59% | |========================================== | 60% | |=========================================== | 61% | |=========================================== | 62% | |============================================ | 63% | |============================================= | 64% | |============================================= | 65% | |============================================== | 65% | |============================================== | 66% | |=============================================== | 66% | |=============================================== | 67% | |=============================================== | 68% | |================================================ | 68% | |================================================ | 69% | |================================================= | 70% | |================================================== | 71% | |================================================== | 72% | |=================================================== | 73% | |==================================================== | 74% | |==================================================== | 75% | |===================================================== | 75% | |===================================================== | 76% | |====================================================== | 77% | |====================================================== | 78% | |======================================================= | 78% | |======================================================= | 79% | |======================================================== | 80% | |========================================================= | 81% | |========================================================= | 82% | |========================================================== | 83% | |=========================================================== | 84% | |============================================================ | 85% | |============================================================ | 86% | |============================================================= | 87% | |============================================================= | 88% | |============================================================== | 88% | |============================================================== | 89% | |=============================================================== | 89% | |=============================================================== | 90% | |=============================================================== | 91% | |================================================================ | 91% | |================================================================ | 92% | |================================================================= | 93% | |================================================================== | 94% | |=================================================================== | 95% | |=================================================================== | 96% | |==================================================================== | 97% | |==================================================================== | 98% | |===================================================================== | 98% | |===================================================================== | 99% | |======================================================================| 99% | |======================================================================| 100%
shp_cospons_incoming[1:5, 1:3]
#> Andreas Broennimann Ueli Maurer Markus Hutter
#> Andreas Broennimann 0 19 29
#> Ueli Maurer 19 0 19
#> Markus Hutter 29 19 0
#> Hansruedi Wandfluh 64 33 68
#> Thomas Matter 0 0 1
shp_cospons_outgoing <- sharedPartner_stat(cospons_mat, directed = TRUE,
triad.type = 'directed.outgoing')
#> | | | 0% | | | 1% | |= | 1% | |= | 2% | |== | 2% | |== | 3% | |=== | 4% | |=== | 5% | |==== | 6% | |===== | 7% | |====== | 8% | |====== | 9% | |======= | 9% | |======= | 10% | |======= | 11% | |======== | 11% | |======== | 12% | |========= | 12% | |========= | 13% | |========== | 14% | |========== | 15% | |=========== | 16% | |============ | 17% | |============= | 18% | |============= | 19% | |============== | 20% | |=============== | 21% | |=============== | 22% | |================ | 22% | |================ | 23% | |================= | 24% | |================= | 25% | |================== | 25% | |================== | 26% | |=================== | 27% | |==================== | 28% | |==================== | 29% | |===================== | 30% | |====================== | 31% | |====================== | 32% | |======================= | 32% | |======================= | 33% | |======================= | 34% | |======================== | 34% | |======================== | 35% | |========================= | 35% | |========================= | 36% | |========================== | 37% | |=========================== | 38% | |=========================== | 39% | |============================ | 40% | |============================= | 41% | |============================= | 42% | |============================== | 42% | |============================== | 43% | |=============================== | 44% | |=============================== | 45% | |================================ | 45% | |================================ | 46% | |================================= | 47% | |================================= | 48% | |================================== | 48% | |================================== | 49% | |=================================== | 50% | |==================================== | 51% | |==================================== | 52% | |===================================== | 52% | |===================================== | 53% | |====================================== | 54% | |====================================== | 55% | |======================================= | 55% | |======================================= | 56% | |======================================== | 57% | |======================================== | 58% | |========================================= | 58% | |========================================= | 59% | |========================================== | 60% | |=========================================== | 61% | |=========================================== | 62% | |============================================ | 63% | |============================================= | 64% | |============================================= | 65% | |============================================== | 65% | |============================================== | 66% | |=============================================== | 66% | |=============================================== | 67% | |=============================================== | 68% | |================================================ | 68% | |================================================ | 69% | |================================================= | 70% | |================================================== | 71% | |================================================== | 72% | |=================================================== | 73% | |==================================================== | 74% | |==================================================== | 75% | |===================================================== | 75% | |===================================================== | 76% | |====================================================== | 77% | |====================================================== | 78% | |======================================================= | 78% | |======================================================= | 79% | |======================================================== | 80% | |========================================================= | 81% | |========================================================= | 82% | |========================================================== | 83% | |=========================================================== | 84% | |============================================================ | 85% | |============================================================ | 86% | |============================================================= | 87% | |============================================================= | 88% | |============================================================== | 88% | |============================================================== | 89% | |=============================================================== | 89% | |=============================================================== | 90% | |=============================================================== | 91% | |================================================================ | 91% | |================================================================ | 92% | |================================================================= | 93% | |================================================================== | 94% | |=================================================================== | 95% | |=================================================================== | 96% | |==================================================================== | 97% | |==================================================================== | 98% | |===================================================================== | 98% | |===================================================================== | 99% | |======================================================================| 99% | |======================================================================| 100%
shp_cospons_outgoing[1:5, 1:3]
#> Andreas Broennimann Ueli Maurer Markus Hutter
#> Andreas Broennimann 0 0 45
#> Ueli Maurer 0 0 0
#> Markus Hutter 45 0 0
#> Hansruedi Wandfluh 15 0 28
#> Thomas Matter 0 0 0Homophily
The homophily_stat()-function can be used to calculate
homophily tendencies in the multi-edge network. Homophily represents the
tendency of nodes with similar attributes to cluster together (i.e.,
nodes interact more with similar other nodes than dissimilar ones) [see @mcpherson2001birds]. The function can be
used for categorical and continuous attributes.
If a categorical attribute is provided (in the form of a
character or factor variable),
homophily_stat() creates a homophily matrix, where nodes of
the same attribute are set to e and dyads with nodes of dissimilar
attributes are set 1.
canton_homophilymat <- homophily_stat(dt$canton, type = 'categorical',
nodes = dt$idMP)
canton_homophilymat[1:5, 1:3]
#> Andreas Broennimann Ueli Maurer Markus Hutter
#> Andreas Broennimann 2.718282 1.000000 1.000000
#> Ueli Maurer 1.000000 2.718282 2.718282
#> Markus Hutter 1.000000 2.718282 2.718282
#> Hansruedi Wandfluh 2.718282 1.000000 1.000000
#> Thomas Matter 1.000000 2.718282 2.718282The option these.categories.only can be used to specify
which categories in the attribute variable should lead to a match. For
instance, if you’d only like to test whether parliamentary members from
the canton Bern exhibit homophily tendencies, you can specify:
canton_BE_homophilymat <- homophily_stat(dt$canton, type = 'categorical',
nodes = dt$idMP, these.categories.only = 'Bern')You can also specify multiple matches, e.g.:
canton_BEZH_homophilymat <- homophily_stat(dt$canton, type = 'categorical',
nodes = dt$idMP,
these.categories.only = c('Bern', 'Zuerich'))The matrix canton_BEZH_homophilymat now reports
homophily values of e for dyads of MPs who are both from Bern or both
from Zurich, compared to all other dyads (set to 1).
Apart from cantonal homophily, party, parliamentary groups, gender and age homophily may play a role in co-sponsorship interactions.
party_homophilymat <- homophily_stat(dt$party, type = 'categorical', nodes = dt$idMP)
parlgroup_homophilymat <- homophily_stat(dt$parlGroup, type = 'categorical', nodes = dt$idMP)
gender_homophilymat <- homophily_stat(dt$gender, type = 'categorical', nodes = dt$idMP)If a numeric variable is provided, the
homophily_stat()-function calculates absolute differences
for each dyad in the network.
dt$age <- 2019 - as.numeric(format(as.Date(dt$birthdate, format = '%d.%m.%Y'), "%Y"))
age_absdiffmat <- homophily_stat(dt$age, type = 'absdiff', nodes = dt$idMP)
age_absdiffmat[1:5, 1:3]
#> Andreas Broennimann Ueli Maurer Markus Hutter
#> Andreas Broennimann 0 5 2
#> Ueli Maurer 5 0 7
#> Markus Hutter 2 7 0
#> Hansruedi Wandfluh 3 2 5
#> Thomas Matter 11 16 9For each dyad , the age of and are subtracted and the absolute value is used in the resultant homophily matrix. It is important to note that the absolute difference statistic is slightly counter-intuitive, since small differences indicate stronger homophily. In the gHypEG regression, this presents as a negative coefficient for strong homophily tendencies.
The zero_values-option can again be used to specify your
own zero-values replacements.
Creating custom covariates
Generally, any meaningful matrix with the same dimension as the dependent variable (i.e., here the co-sponsorship matrix) can be used as a covariate in the gHypEG regression [see @casiraghi2017multiplex].
An example: the data frame dtcommittee contains
information on which committees each MP served on during their time in
office.
head(dtcommittee)
#> idMP
#> 1 Andreas Broennimann
#> 2 Ueli Maurer
#> 3 Markus Hutter
#> 4 Hansruedi Wandfluh
#> 5 Thomas Matter
#> 6 Gabi Huber
#> committee_names
#> 1 Finanzkommission NR
#> 2 Kommission fuer soziale Sicherheit und Gesundheit NR;Finanzkommission NR
#> 3 Kommission fuer Verkehr und Fernmeldewesen NR;Finanzkommission NR
#> 4 Kommission fuer Wirtschaft und Abgaben NR
#> 5 Kommission fuer Wirtschaft und Abgaben NR
#> 6 Kommission fuer Verkehr und Fernmeldewesen NR;Kommission fuer Rechtsfragen NR;Buero NROne potential predictor for co-sponsorship support may be if two MPs shared the same committee seat. When preparing your own matrices, make sure the row- and column names match the dependent variable (here the co-sponsorship matrix).
## This is just one potential way of accomplishing this!
identical(as.character(dtcommittee$idMP), rownames(cospons_mat))
#> [1] TRUE
shared_committee <- matrix(0, nrow = nrow(cospons_mat), ncol = ncol(cospons_mat))
rownames(shared_committee) <- rownames(cospons_mat)
colnames(shared_committee) <- colnames(cospons_mat)
for(i in 1:nrow(shared_committee)){
for(j in 1:ncol(shared_committee)){
committees_i <- unlist(strsplit(as.character(dtcommittee$committee_names[i]), ";"))
committees_j <- unlist(strsplit(as.character(dtcommittee$committee_names[j]), ";"))
shared_committee[i, j] <- length(intersect(committees_i, committees_j))
}
}
shared_committee[1:5, 1:3]
#> Andreas Broennimann Ueli Maurer Markus Hutter
#> Andreas Broennimann 1 1 1
#> Ueli Maurer 1 2 1
#> Markus Hutter 1 1 2
#> Hansruedi Wandfluh 0 0 0
#> Thomas Matter 0 0 0(Attribute-based) Degree measures
The gHypEG regression accounts for combinatorial effects, i.e., degree distributions. Compared to other inferential network models, it is therefore not necessary to specify (out/in-)degree variables. The model can be estimated using average expected degrees. In this case it is wise to specify a degree control matrix:
dt$degree <- rowSums(cospons_mat) + colSums(cospons_mat)
degreemat <- cospons_mat
for(i in 1:nrow(cospons_mat)){
for(j in 1:ncol(cospons_mat)){
degreemat[i, j] <- sum(dt$degree[i], dt$degree[j])
}
}It is also not neccessary to control for activity (outdegree) and popularity (indegree) of different node groups in the standard gHypEG regression. However, if you’d like to test for these effects (because they are part of your hypothesis), the gHypEG regression can be estimated with average expected degrees (i.e., without the degree correction).
For attribute-based outdegree measures, create custom matrices:
age_activity_mat <- matrix(rep(dt$age, ncol(cospons_mat)),
nrow = nrow(cospons_mat), byrow = FALSE)
svp_activity_mat <- matrix(rep(dt$party, ncol(cospons_mat)),
nrow = nrow(cospons_mat), byrow = FALSE)
svp_activity_mat <- ifelse(svp_activity_mat == 'SVP', exp(1), 1)For attribute-based indegree measures, create custom matrices:
Creating the dummy variables to encode the zero values of each covariate
As mentioned above, we usually want to ensure that zeroes observed in covariates do not accidentally define structural zeroes of the model. To clarify the reason we want to take care of this, we can consider the following example. A gHypE regression specifies the relative odds of observing an interaction between two nodes in terms of the covariates and some parameters . More specifically, the relative odds can be seen as . If any of the , then , thus fixing the relative odds to 0 and forbidding interactions between . To deal with the problem, we can add a dummy variable that is 1 wherever is different from 0, and takes a fixed value (usually ), wherever is 0. We can then recode such that all 0 values are turned into 1s. Using the two new variables into the model instead of , allows to estimate the effect of on the interaction odds, wherever there is non-zero values, and fixing a uniform value for the odds of all pairs for which it was not providing information.
The function get_zero_dummy() provides the means to do
so. It takes the covariate that needs to be recoded, and returns a list
containing the original covariate where all zeroes have been recoded to
1s, and a second matrix that serves the purpose of encoding the zeroes
of the covariate.
recip_cospons <- get_zero_dummy(recip_cospons, name = 'reciprocity')
age_absdiffmat <- get_zero_dummy(age_absdiffmat, name = 'age')
shared_committee <- get_zero_dummy(shared_committee, name = 'committee')Part 2: Running gHypEG regressions
Regression set up (how to)
The gHypEG regression can be estimated using the
nrm()-function. The function takes
fit <- nrm(adj = cospons_mat, w = recip_cospons,
directed = TRUE, selfloops = FALSE, regular = FALSE)The adj-object takes the adjacency matrix of the
multi-edge network (i.e., the dependent variable). The
w-object (stands for weights) takes the list of covariates.
All covariates can be combined into one list. The list can be named for
a better overview in the regression output. The
directed-argument can either be TRUE or
FALSE. If set to TRUE, the multi-edge network
under consideration is directed in nature. The
selfloops-argument can either be TRUE or
FALSE. If set to TRUE, self-loops are
considered possible in the network. In the case of co-sponsorship
support signatures, self-loops are not possible by definition and should
therefore be excluded from the analysis. In the case of a citation
network, however, self-loops are possible and meaningful and should be
included from the analysis. The regular-argument can either
be TRUE or FALSE. If set to TRUE,
the gHypEG regression is estimated with estimated average degrees
(specified with the xi-matrix) instead of with the
automatic control for combinatorial effects.
Regression table export (using the texreg package)
The texreg-package can be used to export regression
tables.
Regression with degree correction (standard version)
Co-sponsorship networks have been shown to be structured by reciprocity [@cranmer2011inferential]. Several empirical studies have shown that co-sponsorship networks also exhibit tendencies towards triadic closure [@tam2010legislative]. However, Brandenberger [-@brandenberger2018trading] shows that when estimating co-sponsorship networks as bipartite graphs, the triadic closure effect is non-existent. @craig2015role show that homophily also plays an important role in co-sponsorship networks. We therefore use these predictors to estimate the effect of MPs supporting each other’s bills in parliament.
nfit1 <- nrm(adj = cospons_mat,
w = list(same_canton = canton_homophilymat),
directed = TRUE)
summary(nfit1)
#> Call:
#> nrm.default(w = list(same_canton = canton_homophilymat), adj = cospons_mat,
#> directed = TRUE)
#>
#> Coefficients:
#> Estimate Std.Err t value Pr(>t)
#> same_canton 0.207150 0.015376 13.472 < 2.2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R2:
#> McFadden R2 Cox Snell R2
#> -0.005887399 0.006630307To speed things up, the init-argument can be
specified:
nfit1 <- nrm(adj = cospons_mat,
w = list(same_canton = canton_homophilymat),
directed = TRUE,
init = c(0.208))
summary(nfit1)
#> Call:
#> nrm.default(w = list(same_canton = canton_homophilymat), adj = cospons_mat,
#> directed = TRUE, init = c(0.208))
#>
#> Coefficients:
#> Estimate Std.Err t value Pr(>t)
#> same_canton 0.207151 0.015376 13.472 < 2.2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R2:
#> McFadden R2 Cox Snell R2
#> -0.005887397 0.006630318
texreg::screenreg(nfit1)
#>
#> ============================
#> Model 1
#> ----------------------------
#> same_canton 0.21 ***
#> (0.02)
#> ----------------------------
#> AIC 81552.02
#> McFadden $R^2$ -0.01
#> ============================
#> *** p < 0.001; ** p < 0.01; * p < 0.05The variable same_canton shows a positive coefficient
and is significant. The coefficient of
can be interpreted as follows: The log-odds of MP
co-sponsoring the bill of MP
increase by a factor of 0.21 (the odds
())
if
and
are representatives from the same canton. Since the baseline of the
dummy covariate same_canton is 1, the odds can be
calculated by exponentiating the coefficient over the treatment value
(here
).
nfit2 <- nrm(adj = cospons_mat,
w = c(
recip_cospons,
list(party = party_homophilymat,
canton = canton_homophilymat,
gender = gender_homophilymat),
age_absdiffmat,
shared_committee,
list(online_similarity = onlinesim_mat)
),
directed = TRUE,
init = c(.1,-.9, 1.2, .2, .2, 0, 0,0, -.2,-.1))
screenreg(nfit2,
groups = list('Endogenous' = 1:2,
'Homophily' = c(3:7),
'Exogenous' = c(8:10)))
#>
#> ====================================
#> Model 1
#> ------------------------------------
#> Endogenous
#>
#> reciprocity 0.09 ***
#> (0.01)
#> reciprocity_zeroes -0.87 ***
#> (0.02)
#> Homophily
#>
#> party 1.28 ***
#> (0.02)
#> canton 0.21 ***
#> (0.02)
#> gender 0.19 ***
#> (0.01)
#> age -0.05 ***
#> (0.01)
#> age_zeroes 0.02
#> (0.04)
#> Exogenous
#>
#> committee -0.20 ***
#> (0.03)
#> committee_zeroes -0.14 ***
#> (0.01)
#> online_similarity 0.02 ***
#> (0.00)
#> ------------------------------------
#> AIC 54417.97
#> McFadden $R^2$ 0.33
#> ====================================
#> *** p < 0.001; ** p < 0.01; * p < 0.05Regression without degree correction (and when to use it)
nfit3 <- nrm(adj = cospons_mat,
w = c(
get_zero_dummy(degreemat, name = 'degree'),
recip_cospons,
list(party = party_homophilymat,
svp_in = svp_popularity_mat,
svp_out = svp_activity_mat,
canton = canton_homophilymat,
gender = gender_homophilymat),
age_absdiffmat,
list(agein = age_popularity_mat,
ageout = age_activity_mat),
shared_committee,
list(online_similarity = onlinesim_mat)
),
directed = TRUE, regular = TRUE,
init = c(1,0,0,0, 0.1, 0.5, 0, 0, .1, 0,0, 0,0, .1, .01))
summary(nfit3)
#> Call:
#> nrm.default(w = c(get_zero_dummy(degreemat, name = "degree"),
#> recip_cospons, list(party = party_homophilymat, svp_in = svp_popularity_mat,
#> svp_out = svp_activity_mat, canton = canton_homophilymat,
#> gender = gender_homophilymat), age_absdiffmat, list(agein = age_popularity_mat,
#> ageout = age_activity_mat), shared_committee, list(online_similarity = onlinesim_mat)),
#> adj = cospons_mat, directed = TRUE, regular = TRUE, init = c(1,
#> 0, 0, 0, 0.1, 0.5, 0, 0, 0.1, 0, 0, 0, 0, 0.1, 0.01))
#>
#> Coefficients:
#> Estimate Std.Err t value Pr(>t)
#> degree 9.8881e-01 1.5507e-02 63.7645 < 2.2e-16 ***
#> degree_zeroes -1.2173e+01 8.8351e+03 0.0014 0.99890
#> reciprocity 2.8666e-01 8.2143e-03 34.8980 < 2.2e-16 ***
#> reciprocity_zeroes -1.0098e+00 1.9755e-02 51.1149 < 2.2e-16 ***
#> party 1.0978e+00 1.9629e-02 55.9250 < 2.2e-16 ***
#> svp_in -2.1795e-01 2.1980e-02 9.9157 < 2.2e-16 ***
#> svp_out 1.8140e-01 2.1014e-02 8.6323 < 2.2e-16 ***
#> canton 1.7257e-01 1.5556e-02 11.0935 < 2.2e-16 ***
#> gender 1.0105e-01 1.2700e-02 7.9568 1.766e-15 ***
#> age -4.8691e-02 7.1078e-03 6.8503 7.371e-12 ***
#> age_zeroes -6.9783e-03 3.6410e-02 0.1917 0.84801
#> agein 4.1990e-01 3.6615e-02 11.4679 < 2.2e-16 ***
#> ageout 9.1360e-02 3.6584e-02 2.4972 0.01252 *
#> committee 6.6470e-02 2.7180e-02 2.4455 0.01446 *
#> committee_zeroes -1.4037e-01 1.4045e-02 9.9939 < 2.2e-16 ***
#> online_similarity 8.0352e-02 4.4899e-03 17.8962 < 2.2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> R2:
#> McFadden R2 Cox Snell R2
#> 0.5028769 0.8961995Comparing the two models:
screenreg(list(nfit2, nfit3),
custom.model.names = c('with degree correction', 'without deg. cor.'))
#>
#> =============================================================
#> with degree correction without deg. cor.
#> -------------------------------------------------------------
#> reciprocity 0.09 *** 0.29 ***
#> (0.01) (0.01)
#> reciprocity_zeroes -0.87 *** -1.01 ***
#> (0.02) (0.02)
#> party 1.28 *** 1.10 ***
#> (0.02) (0.02)
#> canton 0.21 *** 0.17 ***
#> (0.02) (0.02)
#> gender 0.19 *** 0.10 ***
#> (0.01) (0.01)
#> age -0.05 *** -0.05 ***
#> (0.01) (0.01)
#> age_zeroes 0.02 -0.01
#> (0.04) (0.04)
#> committee -0.20 *** 0.07 *
#> (0.03) (0.03)
#> committee_zeroes -0.14 *** -0.14 ***
#> (0.01) (0.01)
#> online_similarity 0.02 *** 0.08 ***
#> (0.00) (0.00)
#> degree 0.99 ***
#> (0.02)
#> degree_zeroes -12.17
#> (8835.09)
#> svp_in -0.22 ***
#> (0.02)
#> svp_out 0.18 ***
#> (0.02)
#> agein 0.42 ***
#> (0.04)
#> ageout 0.09 *
#> (0.04)
#> -------------------------------------------------------------
#> AIC 54417.97 59441.71
#> McFadden $R^2$ 0.33 0.50
#> =============================================================
#> *** p < 0.001; ** p < 0.01; * p < 0.05Part 3: Model assessment, network simulations, gof
Model comparisons
Model comparisons can be done using AIC-scores, LR-tests
or the R-squared measures. AIC-scores are the best indicators of model
fit. The gHypEG model can also be fit maximally to the data. This
perfectly fit model cannot be interpreted (since step by step,
additional predictive layers are added and these layers capture
deviances but would need to be interpreted individually), but the AIC
scores can be used to check how far away your models are from it.
fullfit <- ghype(graph = cospons_mat, directed = TRUE, selfloops = FALSE)Predicted probabilities
The omega matrix stored in the nrm-object holds the
relative odds of observing interactions between pairs. It can be used to
calculate marginal effects.
nfit2omega <- data.frame(omega = as.vector(nfit2$omega),
cosponsfull = as.vector(cospons_mat),
age_absdiff = as.vector(age_absdiffmat$age),
sameparty = as.vector(party_homophilymat))
nfit2omega[nfit2omega == 0] <- NA
nfit2omega <- na.omit(nfit2omega)
ggplot(nfit2omega, aes(x = age_absdiff, y = omega, color = factor(sameparty)))+
geom_point(alpha = .1) +
geom_smooth() + theme(legend.position = 'bottom') +
scale_color_manual("", values = c('#E41A1C', '#377EB8'), labels = c('Between parties', 'Within party'))+
xlab("Age difference") + ylab("Tie propensities")+
ggtitle('Model (2): Marginal effects of age difference')
#> `geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'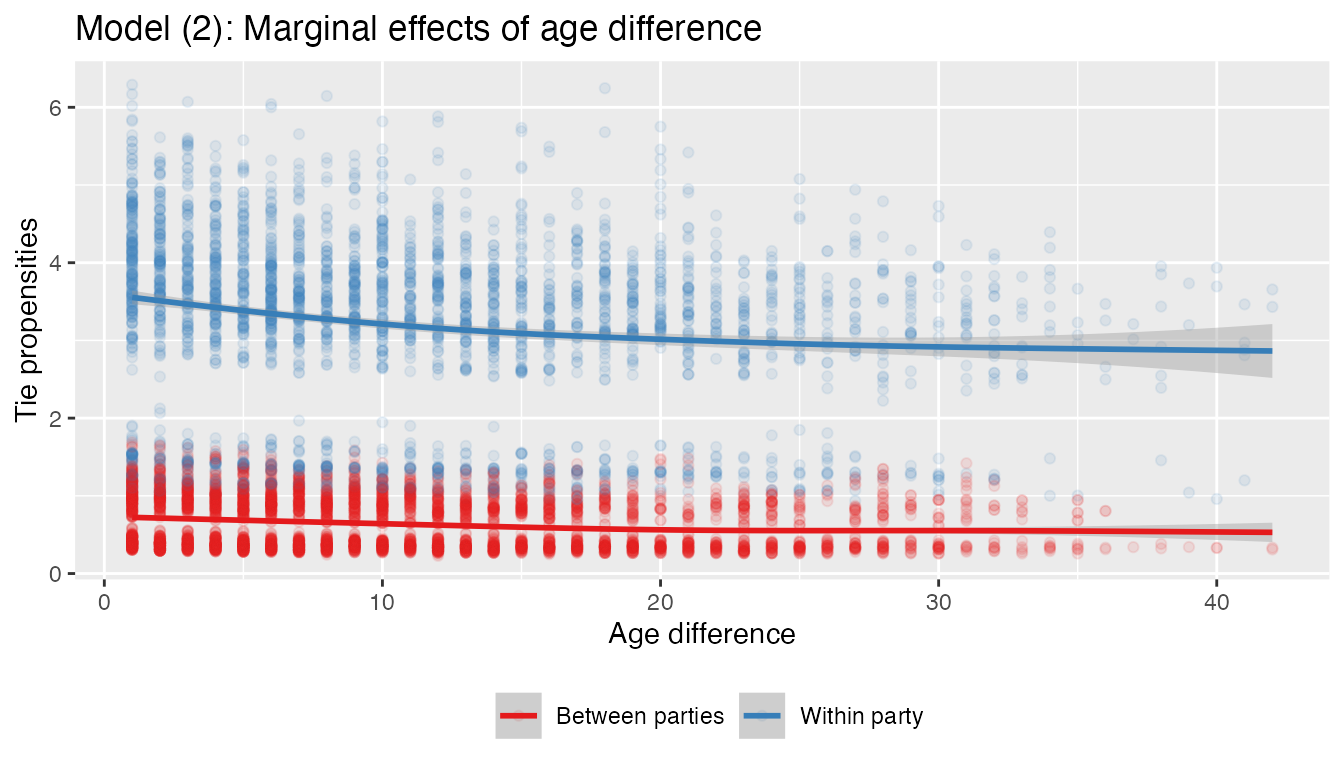
Network simulations
The rghype()-function simulates networks from
nrm-models. The number of simulations can be specified with
the nsamples argument.
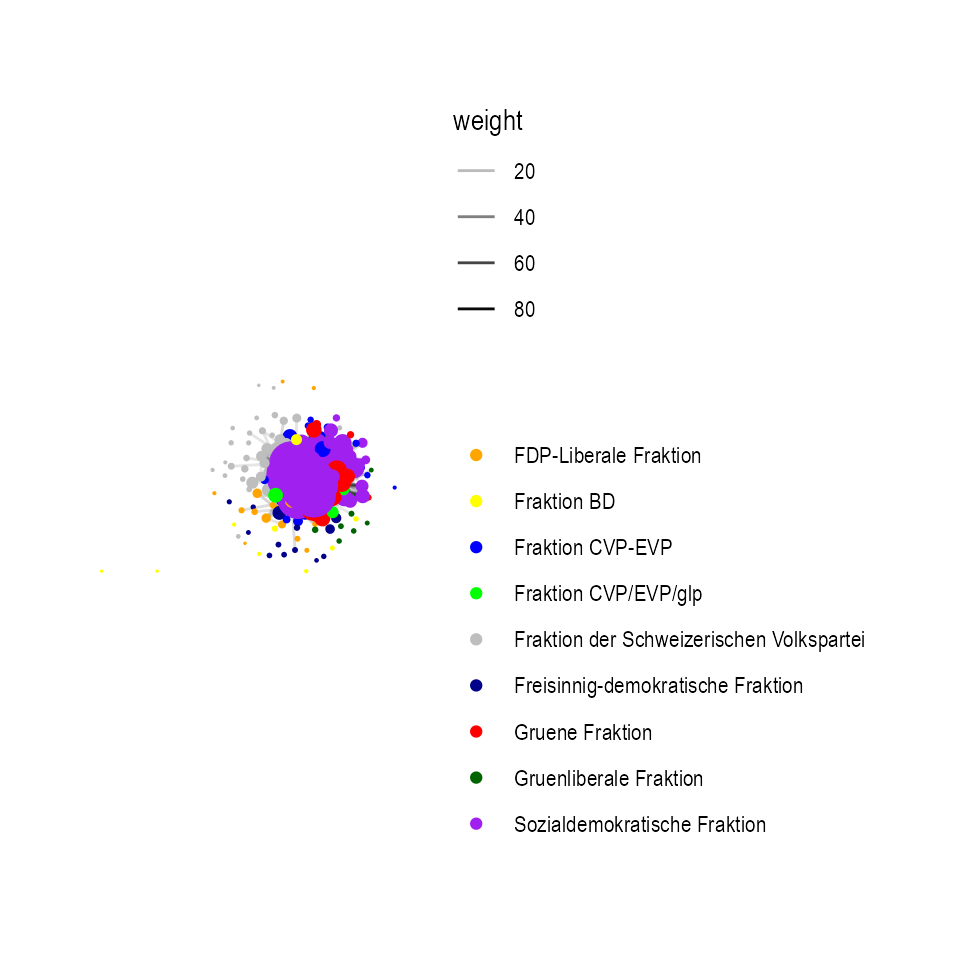
simnw <- rghype(nsamples = 1, model = nfit2, seed = 1253)
ggraph(graph = simnw, layout = 'stress') +
geom_edge_link(aes(filter = weight>5, alpha=weight)) +
geom_node_point(aes(colour = dt$parlGroup), size=10*apply(simnw,1,sum)/max(apply(simnw,1,sum))) +
scale_colour_manual("", values = c('orange', 'yellow', 'blue', 'green', 'grey',
'darkblue', 'red', 'darkgreen', 'purple')) +
theme(legend.position = 'bottom') + coord_fixed() + theme_graph()